Introduction
Data Sturcture
pandas.DataFrame
pandas.Index
pandas.Series
numpy.ndarray
list (built-in)
Conversion
Conclusion
Introduction
The building block for the popular Python package Scikit-learn is the Pandas DataFrame. Python is known for its ease of seamless implicit conversion between data types. Yet, in the case of the DataFrame, some of the APIs and terminology may not feel intuitive. That’s because the underlying data structure is a bit more complex that we tend to perceive.
We may look at it as cells, like in an Excel spreadsheet, which has rows with a row number and and columns with a columns header. Because of this simplistic view, we may be thrown off by the results of some of the DataFrame APIs. For example, You may expect a simple Python list when querying for the column headers or row numbers or column data, but that is not the case.
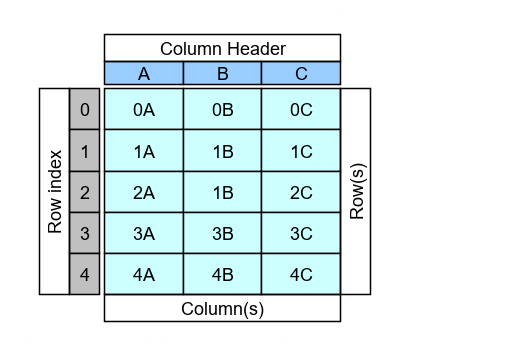
Data structure
> DataFrame is a 2-dimensional labeled data structure with columns of potentially different types. You can think of it like a spreadsheet or SQL table, or a dictionary of Series objects.
Some introductory terminology would be helpful.
- Axes are the 2 dimensions of the table, axis=0 refers to row labels and axis=1 refers to column labels.
- Columns are column labels (or header), not the column data.
- Index refers to the row labels. Though we generally refer to it with implicit row numbers, they can also have explicit labels.
Note: Index is a bit overused in Pandas. Not only are the rows referred to as index, there is also Index objects and the indexing operator [].
It’s important to understand the following Pandas objects to be able to manipulate a DataFrame.
pandas.DataFrame
A Two-dimensional, size-mutable, tabular data where each column can potentially be of different data types. It contains `Index` objects for the axes labels (row labels and column labels). The data can be thought of as a dicttionaary like container for `Series` objects. It supports arithmetic operations on both row data and column data.

In [1]: import pandas
In [2]: df = pandas.DataFrame(data = [['0A', '0B', '0C'],
...: ['1A', '1B', '1C'],
...: ['2A', '2B', '2C'],
...: ['3A', '3B', '3C'],
...: ['4A', '4B', '4C']],
...: columns=['A', 'B', 'C'])
In [3]: df
Out[3]:
A B C
0 0A 0B 0C
1 1A 1B 1C
2 2A 2B 2C
3 3A 3B 3C
4 4A 4B 4C
In [4]: type(df)
Out[4]: pandas.core.frame.DataFrame
pandas.Index
Encapsulation of row and column labels (or axes)Immutable sequence used for indexing and alignment. The row and column labels are encapsulated in Index objects.

In [5]: df.index Out[5]: RangeIndex(start=0, stop=5, step=1) In [6]: type(df.index) Out[6]: pandas.core.indexes.range.RangeIndex In [7]: df.index.values Out[7]: array([0, 1, 2, 3, 4], dtype=int64) In [8]: type(df.index.values) Out[8]: numpy.ndarray In [9]: df.columns Out[9]: Index(['A', 'B', 'C'], dtype='object') In [10]: type(df.columns) Out[10]: pandas.core.indexes.base.Index In [11]: df.columns.values Out[11]: array(['A', 'B', 'C'], dtype=object) In [12]: type(df.columns.values) Out[12]: numpy.ndarray
pandas.Series
Encapsulation of one-dimensional numpy.ndarray containing the column data, row labels and the column label.

In [13]: srs = df['A'] In [14]: srs Out[14]: 0 0A 1 1A 2 2A 3 3A 4 4A Name: A, dtype: object In [15]: type(srs) Out[15]: pandas.core.series.Series In [16]: srs.index Out[16]: RangeIndex(start=0, stop=5, step=1) In [17]: type(srs.index) Out[17]: pandas.core.indexes.range.RangeIndex In [18]: srs.name Out[18]: 'A' In [19]: type(srs.name) Out[19]: str In [20]: srs.values Out[20]: array(['0A', '1A', '2A', '3A', '4A'], dtype=object) In [20]: type(srs.values) Out[20]: numpy.ndarray
numpy.ndarray
When you see a reference to *array*, it invariably refers to the numpy.ndarray as Python does not have a native built-in array data structure.
list (built-in)
list is a native Python mutable sequence, typically used to store collections of homogeneous items.
Conversion
Translating data from each of the above can look intimidating but fortunately, there are some convenient methods for conversion.
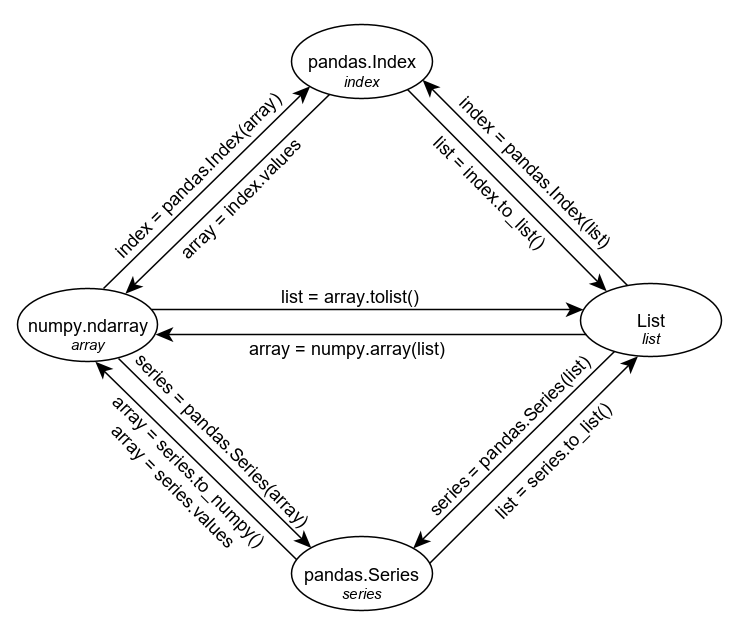
Conclusion
Understanding the data structure will allow you to navigate the Pandas APIs beyond the basic operations.

